基于HBASE的phoenix操作以及hive对hbase的对接工作.
1 phoenix对hbase的操作
1.1 DDL
- 只通过phoenix建表
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
- 首先hbase建表,然后通过phoenix映射成一张表
1.2 DML
1.2.1 查询
语法:
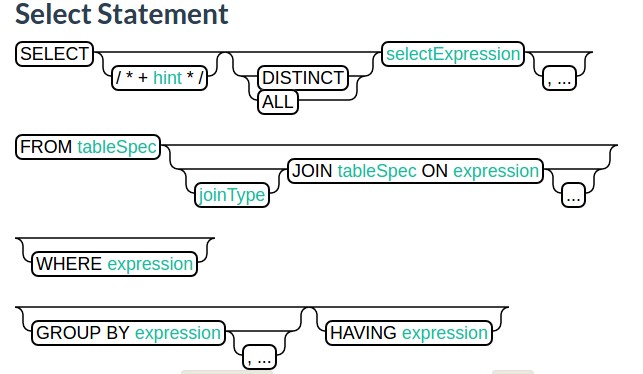
其中:joinType: left, inner, right
- 单查询
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum" FROM us_population GROUP BY state ORDER BY sum(population) DESC; - 关联查询
select a.state from us_population a inner join us_population b on a.state = b.state;
1.2.2 upsert(update or insert)
- 如果支持atomic,需要使用关键字: ON DUPLICATE KEY(availabe from 4.9),它会首先从表里读出记录,然后更新非关键字字段,最后commit到表中。
upsert into tbl_name (key1,key2) values (key1_value,key2_value) on duplicate key update col1=value or expression
- 如果表里存在关键字相同的记录,而你又不关心,可以使用ignore字段来忽略。
upsert into tbl_name (key1,key2,col1,col2...) values (key1_value, key2_value, col1_value, col2_value...) on duplicate key ignore. - 简单粗暴:将主键、非空字段以及需要更新的字段列举出来即可
upsert into tbl_name (key1,key2, col3) values (key1_value, key2_value, col3_value);
1.2.3 upsert select
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100;
UPSERT INTO foo SELECT * FROM bar;